DAS ü WELT Bild
von Bundeskanzler Kohl vor den Bundestagswahlen 1987
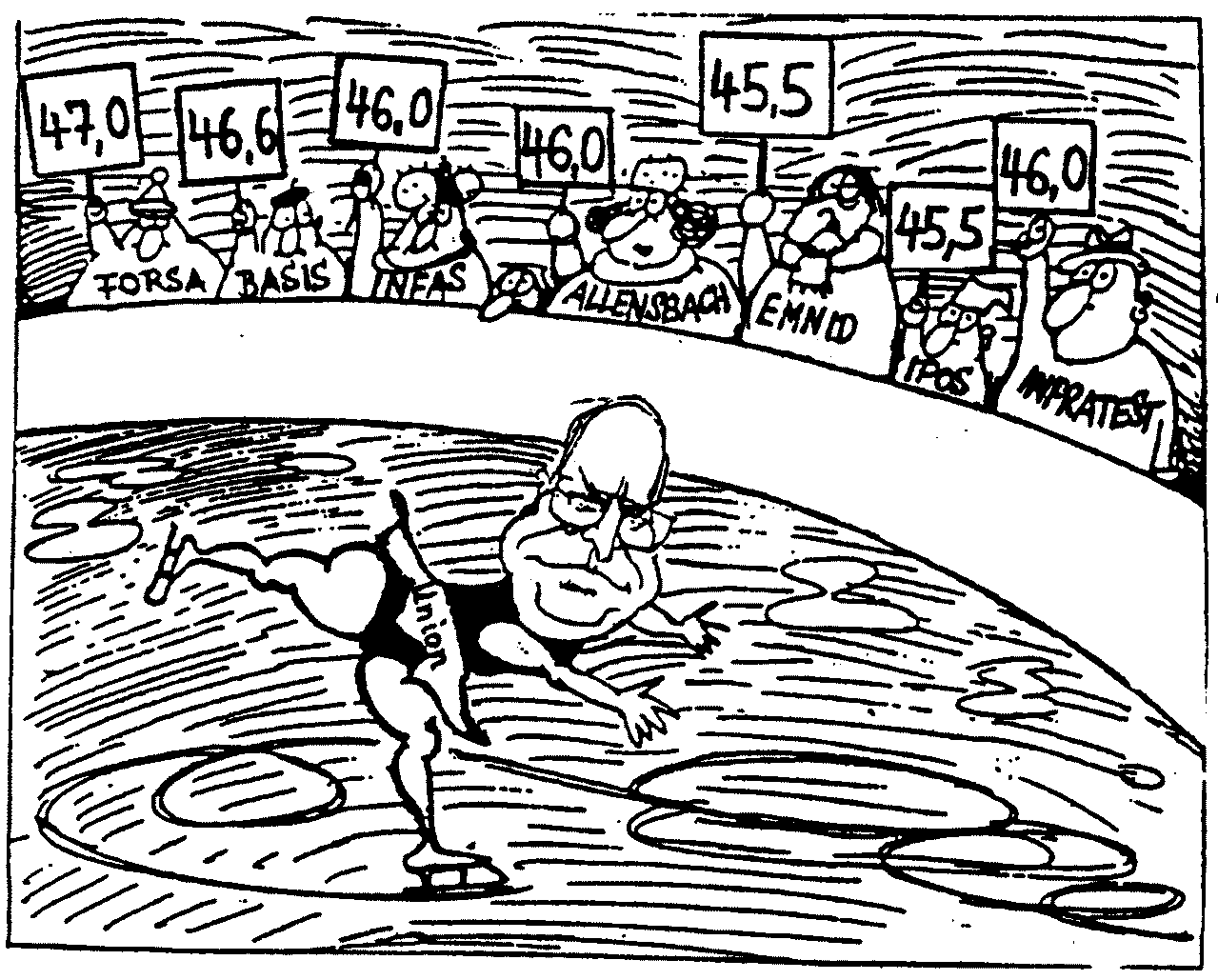
frei nach Mannheimer Morgen
Diagnose : Die Mitglieder der Jury haben geschummelt. Sie haben ihre Umfrageergebnisse solange umgewichtet, bis die vorherrschende Meinung herauskam.(*)
Die Stunde der Wahrheit - die Wahl - begeht der Wahlforscher feierlich, etwas abgespannt durch die Strapazen des Wahlkampfes, aber innerlich gestärkt durch den erhöhten Umsatz. Das Resultat wird er ernüchtert, aber sprudelnd wie ein Fußballreporter kommentieren. Hat er - wie es in der letzten Zeit häufiger passierte - mit Dichtung und Gewichtung Pech gehabt, dann wird er an der Gewichtungsschraube weiterdrehen. Ist er mit der zuletzt verwendeten Gewichtung mal nicht auf die Nase gefallen, so wird er dies der neuen "Methode" zuschreiben. Weshalb sollte er sich die Freude mit der Einsicht vergällen, dass der Erfolg wohl darauf beruht, dass der Zufalls- und Interviewfehler "versehentlich" weggewichtet wurden? Auch ein blindes Huhn findet mal ein Korn.
So oder so: Die Launen des Zufalls werden dafür Sorge tragen, daß die Gewichtungszauberlehrlinge nicht zur Ruhe kommen. "Die Rohzahlen waren oft genauer als die gewichteten Zahlen", jammerte der Geschäftsführer von Basis-Research in der Wirtschaftswoche Nr.1/2 Januar 1987.
Die Wahl wird man überstehen, der Konkurrenz ging es auch nicht besser. Ein Gang nach Canossa? Ein Einkaufsbummel ins nahegelegene Florenz schon eher. Und dann eine Erholungsreise an den Golf von Korinth, verbunden mit einem Kulturtrip zu den Tempeln in Delphi.
Auf dem Flug von Mailand nach Athen schlägt man noch schnell im Reiseführer das Wissenswerte zum "Orakel von Delphi" nach:
"Delphi (7.Jh.v.Chr.) liegt am Südhang des Parnaß (2459m), welcher im Altertum als Sitz des Gottes Apollo galt. Das Orakel Apollos war das berühmteste Orakel des Altertums. Seine große politische Bedeutung fällt in die archaische Zeit. Damals wirkte das Orakel auf die Verfassung der Städte, die Kolonisation und viele politische Unternehmen ein. Noch Platon erkannte Delphis Weisungen eine hohe Bedeutung für die staatliche Ordnung zu."
Die Ausführungen über den großen politischen Einfluss des Orakels bringen unsere Wahlforscher so richtig auf den Geschmack. Dass selbst Platon die Demoskopie und ihre Weisungen für das Wohl der Gemeinschaft und die Aufrechterhaltung der politischen Ordnung als segensreich betrachtete, macht unseren Wahlforschern wieder Mut. Welch gute alte Zeit! Anstatt den Glauben an die eigenen Prognosen sich beim Nervenklempner auf der Couch ausreden zu lassen, könnte man es doch einmal mit dem Orakel versuchen, das seine Kunst noch beherrschte.
Im Reiseführer erfährt man, wie eine Konsultation beim Orakel abläuft:
Das Medium von Delphi war eine ältere Frau: die Pythia
Nach einer Opfergabe nahmen die Pythia und ihre ratsuchenden Klienten ein gemeinsames Bad in dem kastalischen Springbrunnen, wo ihr die Probleme vorgelegt wurden. Nach diesem Ritual ging sie in den Tempel und begann mit der Meditation. In ihrem veränderten Bewußtseinszustand fing die Pythia zu sprechen an. Ihre Wahrsprüche wurden den Ratsuchenden nicht direkt mitgeteilt, sondern sie wurden von Priestern interpretiert und in kunstvollen Versen niedergeschrieben, deren Auslegung nicht immer einfach war.
Auf der Fahrt nach Delphi beraten unsere Wallfahrer, was sie der Orakelpriesterin Pythia als Opfergabe bieten könnten. Sie einigen sich auf ein Wertpapier und legen ihre letzte Prognose auf den Altar. Vom Schatzmeister des Tempels nach Nominal- und Kurswert befragt, erwiderten sie beflissen, solche Papiere würden selten zum Nennwert genommen und die Kotierung an der Gerüchtebörse sei erst kürzlich erfolgt. Entscheidend sei aber der innere Wert, und der Selbstkostenpreis habe fast 100.000,- DM betragen. Der Schatzmeister erwidert sachlich aber höflich, der Altar sei keine Endlagerungsstätte und fünf Mark in bar wären ihm lieber. Nach dieser kalten Dusche ist unseren Wahlkampfmanager die Lust auf ein Bad im Nymphen-Springbrunnen vergangen und die Pythia verlegt die Reinigungsprozedur in die Sauna. Dort tragen sie ihr das manische-depressive Leiden des repräsentativen Querschnittes vor:
seine Wankelmütigkeit !
Den Wahrspruch der Pythia am nächsten Morgen
- Achte das Einmaleins der Statistik -
haben unsere Wahlforscher bis heute nicht enträtselt. Als Datenhändler hat man nicht viel Zeit zur Muße, auch werden sie den Verdacht nicht los, dass die Pythia sie im Dampfbad mit der Konkurrenz aus "Wetten dass ..." verwechselt hat. Wie dem auch sei, solange unsere Polit-Wetterfrösche für ihre gewichteten Lottozahlen dank der guten Tarnung reißenden Absatz finden, und jedermann - von Politikern bis hin zur Regenbogenpresse - diesem Zahlen-Horoskop hörig ist, verhallt der Wahrspruch der Pythia ungehört. Man kann von unseren Datenhändlern - Kreuzritter für freies Unternehmertum - auch nicht erwarten, daß sie sich freiwillig in den eigenen Speck schneiden. Das wäre gänzlich neu in einer freien, aber nicht Narren-freien Marktwirtschaft.
In Meinungsforschungskreisen ist die "Pythia vom Bodensee" eine wohlbekanntes und ein wohlbeachtetes Phänomen.
Bei dieser Institution handelt es sich aber nicht um eine Reinkarnation der Pythia in unserem Jahrhundert - allenfalls um eine von der Frankfurter Allgemeinen (FAZ) bestellte Thronräuberin - sondern um den Kosenamen von Frau Prof. Dr. Dr. h. c. Noelle-Neumann im eingeweihten Blätterwald.
Daß zwischen den beiden Damen Welten liegen, oder, wie wir in der Schweiz zu sagen pflegen, sie ihr Heu nicht auf der gleichen Bühne haben, geht auch aus dem "Wahr"spruch der "Pythia vom Bodensee"
Die Schweigespirale, Öffentliche Meinung - unsere soziale Haut
hervor, der mit dem Einmaleins der Statistik auf Kriegsfuß steht, soweit es die Anwendung auf die Gegenwartspolitik betrifft.
In den Auswirkungen auf die Staatspolitik ist jedoch eine gewisse Parallelität zwischen den beiden Damen unverkennbar. Ich kann mir allerdings nicht vorstellen, daß Platon der "Pythia vom Bodensee" die Prozentzahlen ebenso aus der Hand gefressen hätte wie Helmut Kohl.
DAS ü WELT Bild
von Bundeskanzler Kohl vor den Bundestagswahlen 1987
frei nach Mannheimer Morgen
Diagnose : Die Mitglieder der Jury haben geschummelt. Sie haben ihre Umfrageergebnisse solange umgewichtet, bis die vorherrschende Meinung herauskam.(*)
(*) Auf der Basis von 1000 Interviews besteht nämlich eine Chance von weniger als 1%, daß die Resultate von sieben unabhängigen Meinungsforschungsinstituten einen Spielraum von lediglich 45,5% bis 47% aufweisen. Selbst bei 2000 Interviews liegt diese Chance noch deutlich unter 5%
Erste-Hilfe-Kurs in Statistik

Siamesische Kür frei nach Mannheimer Morgen
Diese Arbeit wurde durch eine Anfrage der Zeitschrift für Markt-, Meinungs- und Zukunftsforschung angeregt. Die Durchführung wurde durch ein vorzeitig gewährtes Forschungs-Freisemester ermöglicht. Die Arbeit stellt das Resultat einer Teamarbeit unter meiner Anleitung dar. Mein besonderer Dank geht an Edith Achiman und Ullrich Tesche.
Für Korrekturen und redaktionelle Vorschläge danke ich Thomas Hochkirchen und Frank Sauder. Bernd Wallaschkowski bemühte sich um die Textverarbeitung mit seinem privaten PC.
Ohne die zahlreichen Gespräche mit Nichtstatistikern - u. a. mit W. Huncke, G. Pinkernell und meiner Frau - die mich mit ihren Fragen oft zur Verzweiflung trieben, hätte ich nicht versucht, den statistischen Jargon über Bord zu werfen und die Auslosung des repräsentativen Querschnittes zum Mittelpunkt meiner Darstellung zu machen.
Ich danke meinen Kollegen und Studenten G. Heindl, H. Hoffmann, H. Scheid, E. Scholz, D. Vogt und A. Zieschang sowie meiner Frau und Herrn M. Kroemer für die kritische Durchsicht der verschiedenen Fassungen des Manuskriptes. Durch ihre Fragen und Vorschläge wurde die Gestaltung der Arbeit verbessert.
Ich danke Herrn Witte vom Uni-Rechenzentrum für seine Kooperation bei der Durchführung der vielen Simulationen.
Ich danke Yolanda Aguado, Ruth Horine und Martine Mérigeau sowie Agustin Blanco-Roiz und Gilbert Liébray für die Übersetzung der Zusammenfassung ins Französische und Spanische. Durch ihre Rückfragen und die daraus resultierenden Gespräche wurde die Gestaltung wesentlich verbessert.
Mein Dank geht auch an den Demokrit Verlag und an Herrn G. Wickert für die gewährte Unterstützung und für ihre Engelsgeduld.
Der Lotteriecharakter des repräsentativen Querschnittes
Wahlprognosen und Meinungsumfragen
und der Ablaßhandel mit Prozentzahlen
Zusammenfassung
Das Ziel dieser Arbeit besteht darin, dem Nicht-Statistiker mit Hilfe von frappanten Beispielen und zugespitzten Formulierungen klar zu machen, daß die Meinungsforscher in der Bundesrepublik ihre hochtrabenden Versprechen betreffend Wahlprognosen seit über dreißig Jahren aus statistischen Gründen nicht einhalten können. Zunächst wird gezeigt, daß der fromme Spruch vom "repräsentativen" Querschnitt - im Sinne eines Spiegel- oder Miniaturbildes der Bevölkerung - ein reiner Etikettenschwindel ist. Es ist aus mathematischen Gründen unmöglich, Miniaturbilder zu realisieren, die aus 1000 oder 2000 Personen bestehen. Sogar mit 10000 Personen geht es nicht, aber dann wären Meinungsumfragen wenigstens "unbezahlbar", und die meisten Probleme würden sich erst gar nicht stellen. Selbst wenn Miniaturbilder eines Tages durch höhere Gewalt auf die Welt gebracht würden, könnten sie die völlig unrealistischen Vorstellungen und Erwartungen der Meinungsforscher und ihrer Kunden nicht erfüllen.
Durch das Suggestivwort "repräsentativer" Querschnitt wird bei den Konsumenten und Auftraggebern von Meinungsumfragen der Eindruck erweckt, die gelieferten Daten seien glaubwürdig und zuverlässig. Die Autorität des "repräsentativen" Querschnittes löst bei vielen eine Art Verpflichtung und Resignation aus, sich mit der gelieferten Information abzufinden, als hätte die große Mehrheit der Bevölkerung ganz persönlich zu ihnen gesprochen. Jeder Branchenkundige weiß jedoch, daß es die Zufallsstichprobe ist - d.h. eine per Lotterie getroffene Auswahl - welche die mit dem Werbeslogan "Repräsentativumfrage" gemachten Versprechen einlösen soll (von den Quotenstichproben sehen wir fürs erste ab ...). Die Auswahl per Lotterie liefert zwar viel bessere Resultate, als der Laie sich vorstellen kann, aber bei weitem nicht so gute, wie die Prognoseindustrie und ihre stille, aber äußerst geschickte Lobby seit Jahrzehnten behaupten. Mit Computersimulationen läßt sich zeigen, daß die Auswahl per Lotterie in "repräsentativen" Querschnitten größere Abweichungen verursacht, als bisher angenommen wurde. Dies macht es praktisch unmöglich, auf die Fragen nach den politischen Kräfteverhältnissen in der Bundesrepublik verbindliche Antworten zu geben, weil relativ geringe Verschiebungen die politische Situation grundlegend verändern können.
Im Gegensatz zu anderen Ländern bewegen sich hier die Änderungen der relevanten Parteistärken in engen Grenzen. Seit 1965 lagen beispielsweise die Resultate für die CDU/CSU zwischen 44,3% und 48,8%, für die SPD zwischen 37,0% und 45,8% und für die FDP zwischen 5,8% und 10,6%. Zählt man ab 1983 bei der SPD die Grünen hinzu, die zu einem guten Teil von der SPD "abgewandert" sind, dann reduziert sich der Bereich der SPD auf 39,3% bis 45,8%. Im Vergleich dazu weisen die üblichen Vertrauensintervalle - deren Aufgabe bekanntlich darin besteht, Aufschluß darüber zu geben, in welchem Umfang der "repräsentative" Querschnitt durch auslosungsbedingte Abweichungen verzerrt sein kann - ein Ausmaß von ±2% bis ±4% auf. Wie man sieht, liegen die Vertrauensintervalle in der Größenordnung der historischen Schwankungsbreiten der Parteistärken und übersteigen diese sogar gelegentlich. Der "repräsentative" Querschnitt kann also wegen der auslosungsbedingten Fehler nicht mehr Information liefern als die vorangehenden Wahlresultate, oft sogar weniger.
Bei dieser Sachlage bleibt den Wahlforschern "nur" der Ausweg, die auslosungsbedingten Abweichungen unter den Teppich zu kehren. Die Bekanntgabe von aktuellen Wahlprognosen in statistisch vertretbarer Form, d.h. unter Angabe der auslosungsbedingten Abweichungen wie z.B.
CDU/CSU 42% - 50%, SPD 35% - 43%, FDP 5% - 10%, Grüne 4% - 9%
würde so lächerlich wirken, daß sie nur in Witzblättern oder als Comic-strip möglich wäre. Wer würde für eine solche Banalität 50000 Mark hinblättern? Noch ärgerlicher wäre der laufende Einnahmeausfall, denn für den gleichen faulen Witz kann man nicht jede Woche abkassieren.
Also tun die Wahlforscher so, als hätten sie das statistische Ei des Columbus entdeckt: Eine magische Formel, welche die auslosungsbedingten Fehler in nichts auflöst. Mit Hilfe einer Umgewichtungsprozedur, deren alchimistischer Gehalt unverkennbar ist, wird den Vertrauensintervallen die überschüssige Luft abgelassen, und alsdann schlüpfen "exakte Zahlen" aus der Retorte, bis hin zur Stelle nach dem Komma. Dieses Vabanquespiel basiert auf einer Umgewichtung der aktuellen Umfrageergebnisse in Abhängigkeit vom früheren Wahlverhalten (sogenannte Recall-Frage). Der statistische Gehalt dieser "Einkommens-umverteilung" im Prozentbereich beruht auf dem folgenden "Gedankengang": Falls die Wähler die Absicht haben, für die gleiche Partei zu stimmen wie bei der letzten Wahl vor vier Jahren, und falls sie dies dem Interviewer anvertrauen - unsere Wahlforscher hoffen also, daß die Wähler ihre Gedächtnislücken selbst "reparieren", auch diejenigen, die damals noch nicht wahlberechtigt waren oder seither gestorben sind - ja, dann funktioniert die Umgewichtung statistisch tadellos. Abgesehen davon braucht man unter diesen Annahmen weder Meinungsumfragen noch eine Wahl durchzuführen, um Resultate zu erhalten. Man kopiere einfach die Resultate der letzten Wahl ....
Tragischerweise entpuppt sich das Ei des Columbus unserer Wahlforscher in der Praxis als Kuckucksei. Die alchimistische Recall-Formel produziert häufig surrealistische Resultate, die nicht zu vermarkten sind. So sind weitere Meinungsklima-Kuren vonnöten, deren phantasievolle Nomenklatur den höchsten Ansprüchen genügt. Ein Schönheitsfehler mag darin bestehen, daß das Endresultat ganz anders ermittelt wird: Eine Prognose wird einfach so gemacht, daß das letzte Wahlresultat in Abhängigkeit von der vermeintlichen politischen Windrichtung Pi mal Daumen ein bißchen nach oben oder unten korrigiert wird. Die aktuellen Umfrageergebnisse spielen dabei eine untergeordnete Rolle. Sie dienen allenfalls dazu, die vermeintliche politische Windrichtung zu ermitteln. In Anbetracht der unkontrollierbaren auslosungsbedingten Abweichungen und Interviewfehler erfordert dieses Abenteuer jene Mischung von grenzenlosem Selbstvertrauen und unerschütterlicher Ahnungslosigkeit, welche sonst zum Rüstzeug von Politikern gehören. Die laufend feilgebotenen Prognosezahlen für die sogenannte Sonntagsfrage
"Wie würden Sie wählen, wenn am nächsten Sonntag Bundestagswahl wäre?"
reflektieren also ausschließlich die Spekulationen der Wahlforscher, oder, wie sie es salbungsvoll ausdrücken: ihre Gewichtungskunst.
Bei dieser Sachlage versteht es sich von selbst, daß Trendangaben keinen Bezug zur Realität haben, weil sie durch auslosungsbedingte Pseudo-Trends bis zur Unkenntlichkeit entstellt sind. Um es boshaft auszudrücken: Die "Gunst" des Zufalls beschert den Wahlforschern laufend Neuigkeiten und Schlagzeilen. Was sich wirklich abspielt, das weiß kein Mensch, und die von den Meinungsforschungsinstituten gelieferten Daten über das zeitliche Auf und Ab der Parteistärken - z.B. CDU/CSU -2,8%, SPD +1,9%, FDP +1,3%, Grüne -0,4% - haben ungetrübten Horoskop-Charakter. Sie täuschen Veränderungen vor, die quantitativ mit an Sicherheit grenzender Wahrscheinlichkeit falsch sind und die häufig nicht einmal qualitativ richtig sind.
Diese Probleme werden dadurch potenziert, daß in der Meinungsforschung ein falsches statistisches Modell zur Anwendung kommt: die Binomialverteilung und ihre Approximation - die Normalverteilung. Beide sind bei den empirischen Sozialforschern auf der ganzen Welt populär. Diese Verteilungen belohnen den glücklichen Gläubigen mit den kleinstmöglichen Vertrauensintervallen - die von der Auslosung des "repräsentativen" Querschnittes verursachten Abweichungen werden also minimal. Was will er mehr? Er wird nicht belohnt, wenn er der Tatsache ins Auge sieht, daß dieses Modell in keiner Weise eine statistisch legitime Beschreibung seiner Meinungsumfrage darstellt, sondern der Ausdruck von reinem Wunschdenken ist, das von einer Generation von Lehrbüchern auf die nächste vererbt wird, wie ein Fluch bis ins dritte und vierte Geschlecht. Das Modell unseres Gläubigen setzt voraus, daß die von ihm organisierte Meinungsumfrage aus einer einzigen Frage besteht, die mit "ja" oder "nein" zu beantworten ist. Jede Hausfrau weiß, daß es nicht genügt, einmal "nein" zu sagen, wenn der Interviewer vor der Tür steht. Es ist ihr sonnenklar, daß der ungebetene Gast - der sich an einem schönen Nachmittag unvermittelt in ihrem Wohnzimmer festsetzt - ihr mit seinem seitenlangen Fragebogen ein Loch in den Bauch fragen wird und daß sie vor lauter Möglichkeiten oft nicht weiß, welche Antwort sie geben soll. Statistisch bedeutet dies, daß das korrekte Modell für eine Meinungsumfrage nicht aus einer Binomialverteilung besteht, sondern aus dutzenden von Multinomialverteilungen mit verschiedenen Freiheitsgraden, die gleichzeitig betrachtet werden müssen, was - wenn überhaupt - meist nur mit einer Computersimulation möglich ist. Die Berechnung von Vertrauensintervallen bei Umfragen mit Hilfe der Normalverteilung erinnert an jenen Metzger, der eine Wurst in ein Rudel von Hunden wirft und dann jedem Besitzer den Schmaus in Rechnung stellt. Gewiß kann kein Besitzer beweisen, daß es nicht sein Hund war, der die Wurst erwischte. Dennoch ist der Metzger kein Modell für Integrität. Solche "Vertrauensintervalle" haben die Funktion von statistischen Alibi-Übungen und Milchmädchenrechnungen.
Computersimulationen von Zufallsstichproben zeigen, daß solche Vertrauens-intervalle bis zu 100% oder mehr vergrößert werden müssen, damit die gewählte statistische Sicherheit eingehalten werden kann. Je umfangreicher die Meinungsumfrage, desto größer der Zuschlag. Die Größe der tatsächlichen Vertrauensintervalle hängt von der Anzahl der Fragen und der Antwortmöglichkeiten ab und nicht allein von der Anzahl der Interviews und der statistischen Sicherheit, wie bisher angenommen wurde. Auf den Punkt gebracht: Unter der Glut der Simulations-Sonne schmelzen Berge von angeblich so harten Daten wie Butter.
Wenn der berühmte Psychologe Carl Gustav Jung - der Entdecker und Erforscher des kollektiven Unbewußten - noch lebte, würde er sich wohl gezwungen sehen, seine lange Liste kollektiver Inhalte durch einen weiteren Archetyp zu ergänzen: Zahlengläubigkeit.
Die Alchimisten vergangener Zeiten würden ihre heutigen Kollegen wohl beneiden. Was jenen während Jahrhunderten mangels geeigneter Stoffe und Know-how versagt blieb, ist für unsere Meinungsforscher zur Routine geworden:
aus Prozentzahlen und Aberglauben eine Goldgrube zu machen.
The lottery aspect of the representative sample
Election forecasts and opinion polls
The traffic with percentage points
The purpose of this paper consists in demonstrating to non-statisticians by means of striking examples that for statistical reasons pollsters in the Federal Republic of Germany cannot deliver the goods they have promised the public for the last thirty years. The pious wish of a "representative" sample in the sense of a mirror image or miniature image is shown to be a public relations gimmick. For mathematical reasons it is impossible to construct such images based on 1000 or 2000 people. With 10000 it won't work either, but at least opinion polls would become so costly that most problems would not exist in the first place. Even if miniature images were to be created by an act of God, they could not fulfil the totally unrealistic ideas and expectations of the pollsters and their customers.
The highly suggestive term "representative" sample sounds so reassuring. It brainwashes people into believing that election forecasts and opinion polls must be accurate and reliable. The moral authority of the "representative" sample provokes in many people a feeling of obligation and resignation. They swallow the numbers with which they have been fed, as if the silent majority had spoken to them in person. Everybody in the business knows however that it is random sampling - i.e. the selection by lottery - that is supposed to back up the promise behind "representative" sample, whatever the latter may mean. (As for quota samples ...., we prefer to look the other way.) No doubt the lottery principle leads to much better results than a layman expects, but they are not nearly as good as the forecasting industry keeps claiming ever since it "incorporated" as a pressure group. By means of computer simulations it can be shown that random sampling causes larger errors than has been assumed. These errors make it virtually impossible to provide politically relevant information in the Federal Republic of Germany by means of "representative" samples, because relatively minor changes in party strengths can lead to a completely different political situation.
For in Germany, unlike other countries, the strengths of the dominating parties have traditionally varied in narrow ranges of a few percentage points. For instance, since 1965 the CDU/CSU has varied between 44,3% and 48,8%, the SPD between 37,0% and 45,8% and the swing party FDP between 5,8% and 10,6%. If, as of 1983, one adds the Greens to the SPD (one may consider the former to a large extent as a "spin off" from the latter), then the range of SPD narrows to 6,5% (from 39,3% to 45,8%). By comparison the customary confidence intervals amount to ñ2% to ñ4%. (Recall that their job is to keep you posted on the extent to which the information you get from your sample is distorted by lottery effects.) From this it is obvious that confidence intervals have the same order of magnitude as the historical variations of party strengths and sometimes they are even bigger. This means that "representative" samples provide no more information than the previous elections and often even less.
For this reason the "only" way out for the forecasters is to sweep the lottery effect under the rug. For if they were to divulge their forecasts in a form which could be backed up statistically, i.e. by clearly indicating the errors caused by random sampling, for example
CDU/CSU 42% - 50%, SPD 35% - 43%, FDP 5% - 10%, Greens 4% - 9%,
then their numbers would be eligible for the funny pages. Who would fork out thirty thousand dollars for such a banality? Even worse would be the continual loss of revenue because you can't cash in every week for the same bad joke.
So the pollsters act as if they had discovered the magic formula in statistics which makes random errors evaporate: By means of a weighting procedure, the alchemical origins of which are unmistakable, they first let out the surplus air from the confidence intervals, whereupon "exact figures" down to decimal points hatch out of the retort. Their gamble is based on modifying current voter preferences according to how people voted in the previous election. The statistical gist of their "reallocation" program is the following: If the voters plan to cast their ballots in the same way as they did in the election four years previously and if they confide their intention to the interviewer - our forecasters thus hope that the voters "make up" for their memory lapses, including those who were too young to vote then or have died since - , yes, then everything is perfect in the best of all possible worlds ... and even the statistics of their reallocation system work impeccably. Never mind the fact that under these assumptions you neither need polls nor an election to get results. Just copy the ones from the previous elections ... and there you are.
Tragically the pollsters magic formula frequently produces surrealistic results which they don't dare to sell because they just don't look right. To cover up the further doctoring of half-baked results our pollsters have developed a highfalutin nomenclature which exceeds any standard one might ever have. The minor blemish is that they arrive at the final results in a completely different way: To produce a forecast they merely adjust the results of the last election a little bit upwards or downwards according to the alleged direction of the political trend. They largely ignore current 1poll results and use them, if at all, to determine the alleged direction of the trend. Considering the uncontrollable nature of lottery and interview errors, this adventure requires that blend of unlimited self-confidence and unshakeable ignorance with which usually only politicians are endowed. As for the famous "Sunday-question":
"For whom would you vote if elections were held next Sunday?",
the upshot is that pollsters' results merely reflect their speculation, or, as they put it unctuously - their art of weighting.
From this it is obvious that the trends they report have no bearing on reality whatsoever. For the real trends are so distorted by pseudo-trends resulting from the lottery effect that they become unrecognisable. To put it sarcastically: The favours of chance continually provide our pollsters with news and headlines. In reality nobody knows what is going on. The numbers the pollsters keep dishing out - for instance CDU/CSU -2,8%, SPD +1,9%, FDP +1,3%, Greens -0,4% - contain no more information than a horoscope. They fake changes which are almost surely quantitatively false and are often qualitatively incorrect as well.
These problems are magnified by a wrong statistical model used in demoscopy: the binomial distribution and its substitute, the normal distribution. Both are popular among social scientists throughout the world. They reward the happy believer with the smallest possible confidence intervals - thus the errors due to random sampling become minimal. What more does he want? He gets no rewards for facing the fact that his model is not a legitimate statistical description of the poll he conducts. Instead it is merely a product of wishful thinking which is being handed down from one generation of textbooks to the next like a curse "unto the third and forth generation". For this model assumes that an opinion poll consists of a single question which is to be answered by either "yes" or "no". Every housewife knows that it is not enough to say "no" once, when the interviewer knocks at her door. It is very clear to her that the uninvited guest is going to install himself comfortably in her living room for the afternoon, bombarding her with dozens of multiple choice questions so that she often is at a loss for an answer. Statistically this means that the correct model for an opinion poll does not consist of a single binomial distribution but of dozens of multinomial distributions with different degrees of freedom which have to be taken into account simultaneously. If at all, this can be done only by computer simulations. Computing confidence intervals for opinion polls by means of the normal distribution is reminiscent of that butcher who throws one sausage into a pack of dogs and then charges each owner for the "feast". No owner can prove that it was not his dog that devoured the sausage. Still the butcher is not a model of integrity. Such "confidence" intervals merely serve as a statistical alibi. They have no bearing on reality whatsoever.
Computer simulations of random sampling show that confidence intervals based on the normal distribution have to be increased by 100% or more in order to maintain the chosen probability level. The longer the questionnaire, the greater the increase. The real confidence intervals depend on the number of questions asked and their multiple choice complexity, and not only on the number of people polled and the chosen probability level as has been assumed. In short: under the heat of the simulation-sun vast quantities of allegedly hard data melt down like butter.
If the famous psychologist, Carl Gustav Jung - the discoverer and explorer of the collective unconscious - were still alive, he would feel compelled to extend his long list of collective contents by another archetype:
the happy believer in numbers.
The alchemists of past times would envy their colleagues of today. What they tried to do in vain for centuries for lack of suitable resources and know-how has become routine for our pollsters:
to transform percentage points and superstition into a goldmine.